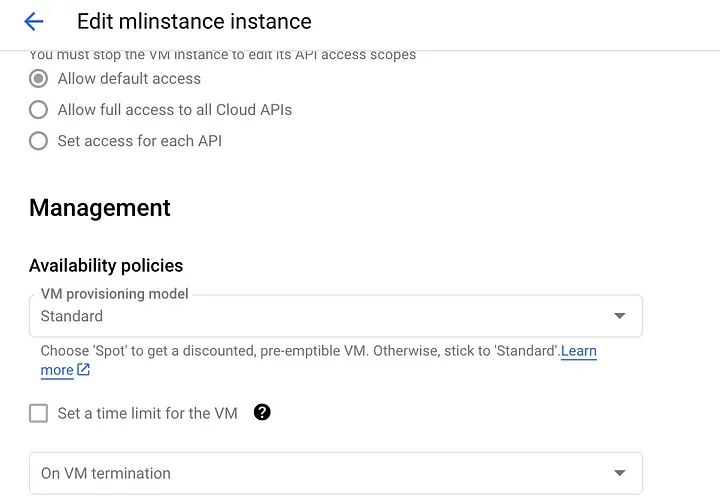
Note: One of the important tips for lab environments is to set an auto-shutdown timer, below is one such setting in GCP
I have been working on a few hosted environments which include AWS Sagemaker Notebook instances, Google Cloud Colab, Gradient (Paperspace) etc and all of them are really good and needed monthly subscriptions, I decided to have my own GPU server instance which can be personalized and I get charged on a granular basis.
Installing it is not easy, first, you need to find a cloud-computing instance which has GPU support enabled, AWS and GCP are straightforward in this section as the selection is really easy.
Let’s break this into 3 stages
- Selecting a GPU server-based instance for ML practice.
- Installing Jupyter Server — Pain-Point Making it accessible from the internet.
- Installing Package managers like Anaconda — Pain-Point having Kernel of conda reflect in Jupyter lab.
Stage-1
For a change, I will be using GCP in this case from my usual choice of AWS here.
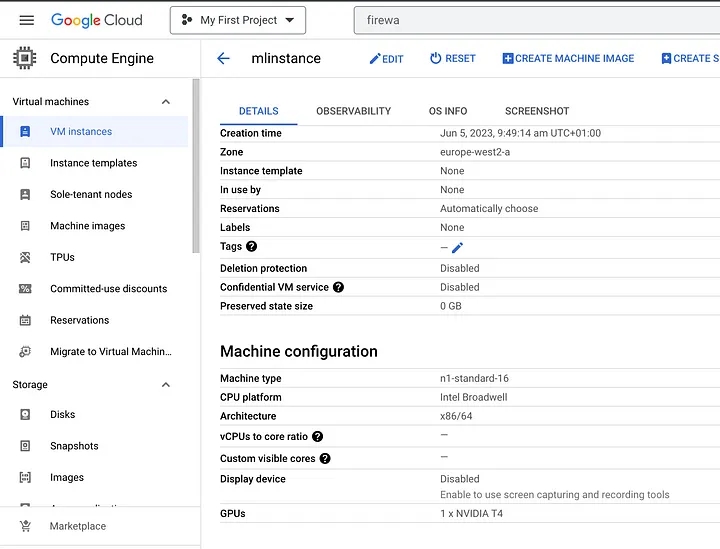
Choose GPU alongside the Instance
Generic Guidelines — https://cloud.google.com/deep-learning-vm/docs/cloud-marketplace
rakesh@instance-1:~$ sudo apt install jupyter-notebook # Step1: generate the file by typing this line in console jupyter notebook --generate-config # Step2: edit the values vim /home/<username>/.jupyter/jupyter_notebook_config.py ( add the following two line anywhere because the default values are commented anyway) c.NotebookApp.allow_origin = '*' #allow all origins c.NotebookApp.ip = '0.0.0.0' # listen on all IPs # Step3: once you closed the gedit, in case your port is blocked sudo ufw allow 8888 # enable your tcp:8888 port, which is ur default jupyter port # Step4: set a password jupyter notebook password # it will prompt for password # Step5: start jupyter jupyter notebook and connect like http://xxx.xxx.xxx.xxx:8888/login? To see GPU Info sudo lshw -C display
Let’s see the GPU-Info
(fastai) r@mlinstance:~$ sudo lshw -C display
*-display UNCLAIMED
description: 3D controller
product: TU104GL [Tesla T4]
vendor: NVIDIA Corporation
physical id: 4
bus info: pci@0000:00:04.0
version: a1
width: 64 bits
clock: 33MHz
capabilities: msix pm bus_master cap_list
configuration: latency=0
resources: iomemory:f0-ef iomemory:f0-ef memory:c0000000-c0ffffff memory:f40000000-f4fffffff memory:f50000000-f51ffffff
(fastai) r@mlinstance:~$
Stage-2 Installing Anaconda
A small script to get the Latest version
cd ~/Downloads
LATEST_ANACONDA=$(wget -O - https://www.anaconda.com/distribution/ 2>/dev/null | sed -ne 's@.*\(https:\/\/repo\.anaconda\.com\/archive\/Anaconda3-.*-Linux-x86_64\.sh\)\">64-Bit (x86) Installer.*@\1@p')
wget $LATEST_ANACONDA
chmod +x Anaconda3*.sh # make it executable
./Anaconda3*.sh # execute the installer
(OR)
curl https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh --output anaconda.sh bash anaconda.sh # After the Install source ~/.bashrc conda list
Stage-3 Associating with Jupyter Notebook
Jupyter Notebook conda install -c conda-forge notebook conda install -c conda-forge nb_conda_kernels Jupyter Lab conda install -c conda-forge jupyterlab conda install -c conda-forge nb_conda_kernels conda install -c conda-forge jupyter_contrib_nbextensions
Creating the environment
conda create --name fastai
conda create -n fastai pip ipykernel # pip and ipykernel are important
conda activate fastai
(fastai)# conda install -c fastchan fastai
(fastai)# conda install paramiko # some random package to test

Selecting the kernel is an important step, I spent lot of time with various other method and finally settled upon this one
-Rakesh